들어가며
회사에서 신규 프로젝트로 검색 고도화를 진행하며 가장 먼저 한 일은 코드 작성이 아니라 검색 로그를 추가하는 일이었습니다. “자동완성을 붙이자”, “오타 교정을 넣자” 같은 아이디어보다 먼저, 무엇을 왜 고쳐야 하는지 판단할 근거가 필요했기 때문입니다.
이번 글에서는 검색 로그로 문제를 정의하고 우선순위를 정한 뒤, 그 판단이 프론트엔드의 입력 보정과 fallback UX, 로그 수집으로 이어진 과정을 정리합니다.
1. 검색이 안 좋다는 말은 너무 추상적이었다
1.1 1,339건의 검색 로그를 분석한 이유
처음에는 “검색이 잘 안 된다”는 피드백만 있었고, 어떤 검색어에서 실패가 반복되는지는 알 수 없었습니다.
그래서 2주치 검색 로그 1,339건을 검색어, 유입 경로, 로그인 여부, 내부 사용자 여부, 검색 결과 수 기준으로 나눠봤습니다.
1.2 로그에서 발견한 세 가지 문제
| 발견 | 수치 | 함의 |
|---|---|---|
| 내부 트래픽 오염 | 전체 로그의 74.2%가 사내 IP | 인기 검색어를 그대로 집계하면 내부 트래픽으로 인한 오염 |
| 광고 유입 비중 | 외부 유입의 70%가 Google/Naver | 광고 클릭 직후의 검색 품질이 전환율에 직결 |
| 비로그인 비율 | 외부 사용자 중 76%가 비로그인 | 개인화 기반 고도화는 시기상조 |
이 세 가지 수치만으로도 우선순위가 바뀌었습니다. 내부 트래픽이 대부분인 상태에서는 인기 검색어를 바로 노출할 수 없었고, 외부 유입의 상당수가 광고에서 들어오고 있었기 때문에 첫 검색 실패가 곧 이탈로 이어질 가능성이 컸습니다.
또한 외부 사용자 중 비로그인 비율이 높았기 때문에, 개인화 검색이나 사용자별 추천보다 비로그인 사용자도 즉시 체감할 수 있는 입력 보정과 검색 실패 수집이 먼저라고 판단했습니다.
2. 사용자는 검색어를 바꿔가며 시스템에 맞추고 있었다
2.1 검색어 유형 분포
외부 사용자 346건의 검색어를 유형별로 분류해보면 다음과 같습니다.
| 유형 | 비율 |
|---|---|
| 브랜드 / 제조사명 탐색 | 19% |
| 노이즈 (타이핑 중) | 9% |
| 자연어 문장형 | 5% |
| 제품군 / 카테고리 | 4% |
| 사용사례 / 공정 | 3% |
| 기타 | 60% |
브랜드 직접 탐색이 19%로 가장 높았고, 자연어 문장형은 5%에 그쳤습니다. 이 비율은 Semantic Search 같은 무거운 인프라를 지금 도입할 필요가 있는가에 대한 판단 근거가 됐습니다.
(Semantic Search: 사용자의 문장을 벡터로 변환해 의미가 가까운 결과를 찾는 방식. ex: “물류 이송에 쓰는 로봇” 같은 문장 의도에 가까운 결과를 찾을 수 있습니다.)
로그에서는 자연어 의도 검색보다 브랜드명·모델명 직접 검색이 훨씬 많았습니다. 따라서 첫 번째 개선은 사용자가 입력하는 브랜드명과 모델명을 더 잘 받아내는 쪽으로 잡았습니다.
2.2 연속 검색 사례
같은 세션에서 사용자가 키워드를 바꿔가며 검색한 연속 사례를 추출해보니, 현재 검색이 무엇을 해결하지 못하는지가 더 또렷해졌습니다.
| 사례 | 연속 검색 흐름 | 원인 | 사용자 의도 |
|---|---|---|---|
| A사 | 핸드 → 5지 → 4지 → finger → hand → DG-5F-S | 같은 카테고리를 키워드만 바꿔 6번 탐색 | 로봇 핸드 그리퍼를 찾고 있음 |
| B사 | 유니트리 → ubtech → leju → fourier → deep robotics | 비교 탐색을 검색으로만 해결 | 휴머노이드 브랜드 비교 |
| C사 | maira → 뉴라보 → 뉴라 → 7축 | 자동완성 부재로 키워드를 좁혀가며 재시도 | 같은 모델(MAiRA)을 찾고 있음 |
| D사 | 2ㅀ7 → 2FG7 | 한/영 키 잘못 누른 오타 | 모델명(2FG7) 입력 시도 |
연속 검색은 검색 실패의 흔적에 가까웠습니다. 사용자가 같은 의도를 유지한 채 표현만 바꿔가며 다시 검색하고 있다는 것은, 현재 검색이 사용자의 표현을 충분히 받아내지 못하고 있다는 뜻이었습니다.
이 지점에서 프론트엔드가 할 수 있는 일도 분명해졌습니다. 사용자가 입력한 값을 그대로 검색 엔진에 넘기는 데서 끝나는 것이 아니라, 한/영 키보드 오타를 보정하고, 결과가 없을 때 다른 형태의 쿼리로 한 번 더 시도하며, 실패한 검색을 이후 개선 데이터로 남기는 역할이 필요했습니다.
2.3 한/영 혼용으로 분산되는 검색
같은 제품이 한글과 영문으로 나뉘어 검색되며 결과가 분산되는 패턴도 두드러졌습니다.
| 영문 | 한글 | 외부 합산 |
|---|---|---|
| agibot | 애지봇 | 11회 |
| ufactory | 유팩토리 | 11회 |
| manus | 마누스 | 9회 |
| unitree | 유니트리 | 7회 |
agibot 과 애지봇 은 같은 브랜드인데도 인덱스에서 별개로 잡혀, 사용자가 어느 쪽을 치느냐에 따라 결과가 달라지고 있었습니다.
3. 문제 유형별로 담당 레이어를 나눴다
분석 결과를 한 장으로 정리하면, 검색 문제는 단일 해법으로 풀 수 있는 것이 아니라 유형별로 다른 기술 스택이 필요한 묶음이었습니다.
| 문제 | 해법 | 담당 |
|---|---|---|
한/영 키보드 전환 오타 (ghqtjs → 로봇) | es-hangul 의 convertQwertyToHangul | 프론트 |
브랜드 표기 변형 (야스카와 ↔ 야스까와) | 자모 분리 + n-gram | 백엔드 + 프론트 |
초성 검색 (ㄹㅂ → 로봇) | getChoseong + *_chosung 필드 | 백엔드 + 프론트 |
한/영 브랜드 매핑 (유니트리 ↔ unitree) | 동의어 쌍 등록 (1:1 매핑) | 백엔드 |
의미 유사 검색 (물류로봇 ↔ AMR) | 벡터 임베딩 | 백엔드 |
검색 인덱스와 동의어 설정은 백엔드 영역이라, 프론트엔드는 검색 엔진을 대체하는 대신 입력을 잘 전달하고 실패를 데이터로 남기는 데 집중했습니다.
4. 프론트엔드와 백엔드가 같은 검색 규칙을 공유해야 했다
4.1 한/영 브랜드 매핑은 Synonyms로 충분했다
agibot ↔ 애지봇, unitree ↔ 유니트리 같은 한/영 매핑은 정의가 분명한 동의어 쌍이라 Algolia Synonyms로 처리하면 끝이었습니다. 같은 대상을 다른 표기로 부르는 케이스에는 동의어가 가장 잘 맞는 방식입니다.
4.2 표기 변형은 동의어로 풀면 운영 비용이 커진다
야스카와, 야스까와, 야쓰까와 처럼 같은 브랜드를 조금씩 다르게 입력하는 케이스는 사정이 달랐습니다. 동의어는 명확히 같은 대상을 연결할 때 효과적이지만, 미세한 표기 변형까지 동의어로 등록하기 시작하면 운영 비용이 급격히 커집니다. 등록 대상 브랜드만 4,000개가 넘는 상황이라 더 그랬습니다.
그래서 한/영 브랜드 매핑은 Synonyms로, 미세한 한글 표기 변형은 자모 분리 + bigram으로 분리해 다루기로 했습니다.
4.3 자모 분리 + bigram fallback
해법은 인덱싱 시점에 텍스트를 자모 단위로 분해한 뒤, 인접한 두 자모를 묶어 bigram으로 만들어 저장하는 방식이었습니다. 프론트엔드에서는 사용자가 입력한 검색어를 같은 규칙으로 변환해 fallback query를 만들어야 했습니다.
야스카와 → 자모 분리 → ㅇㅑㅅㅡㅋㅏㅇㅘ
→ bigram → "ㅇㅑ ㅑㅅ ㅅㅡ ㅡㅋ ㅋㅏ ㅏㅇ ㅇㅘ"
야스까와 → 자모 분리 → ㅇㅑㅅㅡㄲㅏㅇㅘ
→ bigram → "ㅇㅑ ㅑㅅ ㅅㅡ ㅡㄲ ㄲㅏ ㅏㅇ ㅇㅘ"두 문자열의 bigram은 7개 중 5개가 겹칩니다. 통째로 보면 다른 단어지만, 자모 단위로 쪼개면 대부분이 일치하는 셈입니다. 문제는 Algolia가 기본적으로 쿼리 토큰을 AND로 묶어 모든 토큰이 일치해야 결과를 반환한다는 점이었습니다. 이때 optionalWords 로 토큰을 지정하면 “있으면 가산점, 없어도 탈락은 아닌” 조건으로 바뀌어, 일부만 겹쳐도 매칭이 됩니다.
4.4 인덱싱과 검색 양쪽에 같은 변환이 필요했다
이 방식의 제약은 백엔드(인덱스)와 프론트(쿼리) 양쪽이 동일한 변환을 적용해야 한다 는 점이었습니다. 한쪽만 변환하면 매칭 자체가 일어나지 않습니다.
import { disassemble } from 'es-hangul';
function toNgram(text: string, n = 2) {
const jamo = disassemble(text);
return Array.from({ length: jamo.length - n + 1 }, (_, i) => jamo.slice(i, i + n)).join(' ');
}
const ngramQuery = toNgram(query);
// "야스까와" → "ㅇㅑ ㅑㅅ ㅅㅡ ㅡㄲ ㄲㅏ ㅏㅇ ㅇㅘ"백엔드도 인덱싱 시점에 같은 규칙으로 brand_ngram 같은 필드를 만들어 둡니다. 자모 분리 규칙이 한쪽이라도 어긋나면 토큰이 달라져 매칭이 깨지기 때문에, 이 부분은 구현보다 먼저 명세를 맞췄습니다.
4.5 느슨한 매칭은 매칭 토큰 수로 걸러냈다
다만 이 방식은 토큰 한두 개만 겹쳐도 결과에 포함되는 부작용이 있었습니다. 그래서 응답에 포함된 매칭 토큰 수를 기준으로, 일정 비율 이상 겹치는 결과만 클라이언트에서 한 번 더 걸러냈습니다. 속성명(_rankingInfo.words)은 아래 코드에서 직접 확인할 수 있습니다.
const results = await index.search(ngramQuery, {
restrictSearchableAttributes: ['brandNgram', 'modelNgram'],
optionalWords: ngramQuery,
getRankingInfo: true,
});
const totalTokens = ngramQuery.split(' ').length;
const threshold = Math.floor(totalTokens * 0.6); // 60% 이상 매칭
const filtered = results.hits.filter((hit) => hit._rankingInfo.words >= threshold);전체 토큰의 60% 이상이 매칭된 결과만 남기는 식으로, 자모 단위 부분 매칭이 만든 노이즈를 클라이언트에서 한 번 더 좁혀줬습니다.
5. 가장 먼저 처리할 Phase 1을 골랐다
3장에서 나눈 해법은 한 번에 적용할 수 없어 단계로 나눴습니다. Phase 1의 기준은 인프라 추가 없이 바로 적용 가능하고, 이후 개선의 기반 데이터가 되는 항목이었습니다. 관측 환경 정비와 입력 보정이 여기 해당했습니다.
이 단계들이 실제 검색 런타임에서 어떻게 이어지는지를 한 장으로 정리하면 다음과 같습니다. 입력 정규화에서 시작해, 원본 검색이 실패할 때만 초성 검색·키보드 오타 보정·n-gram fallback이 차례로 개입하고, 마지막에 결과를 노출합니다.
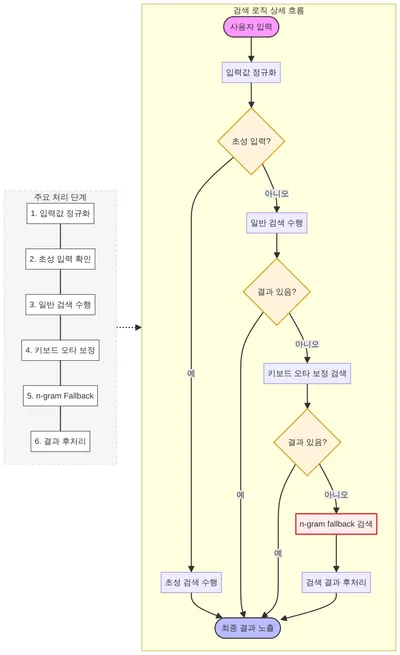
아래 하위 절에서는 이 흐름 중 Phase 1에서 먼저 처리한 관측 환경 정비와 입력 보정을 차례로 살펴봅니다.
5.1 내부 검색을 분리했다
사내 IP 대역의 요청에 is_internal = true 플래그를 붙여 로그 적재 시 분리했습니다. 전체 로그의 74.2%가 내부 트래픽인 상태에서는 어떤 검색어가 실제 사용자 수요인지 판단할 수 없었기 때문에, 인기 검색어 기능보다 기준선을 만드는 작업이 먼저였습니다.
5.2 Zero-result 로그를 수집했다
nbHits === 0 인 케이스를 별도 이벤트로 남겨, 어떤 쿼리에서 사용자가 막히는지 데이터로 쌓이게 했습니다. 이 로그는 동의어 등록 대상을 발굴하는 근거가 되고, fallback 단계에서는 같은 쿼리를 bigram 부분 매칭으로 한 번 더 돌리는 트리거로도 쓰입니다.
5.3 한/영 키보드 오타를 보정했다
ghqtjs → 로봇, ufactiry → ufactory 같은 한/영 키 잘못 누른 입력은 es-hangul 의 convertQwertyToHangul / convertHangulToQwerty 로 양방향 변환해 보정합니다. 다만 항상 동작하면 예측하기 어려운 결과가 노출되기 때문에, 원본 검색 결과가 없거나 매우 적을 때만 fallback으로 실행합니다.
6. 하지 않기로 한 것들도 데이터로 정했다
Semantic Search는 매력적인 선택지였지만, 자연어 문장형 쿼리가 5% 수준인 상태에서 임베딩 서버와 벡터 DB 운영 비용을 감안하면 지금 도입할 단계는 아니었습니다. Phase 1이 자연어 쿼리 상당수를 이미 커버하기 때문에, zero-result 누적과 클릭 로그에서 실제 수요가 확인되면 도입하기로 미뤘습니다.
마치며
이번 프로젝트에서 가장 크게 배운 것은 검색 고도화가 새로운 기술을 더하는 일이 아니라, 어떤 문제를 먼저 풀어야 하는지 데이터로 판단하는 일 이라는 점이었습니다.
- 문제 유형별 해법 분리 — 같은 “검색이 안 된다”는 신호도 원인이 다르면 해법이 다릅니다
- 데이터 누적 선행 — CTR 재정렬도 Semantic Search도, 데이터가 없으면 의사결정 자체가 어렵습니다
- 프론트엔드의 자리 — 검색 행동이 발생하는 가장 앞단에서 입력 마찰을 줄이고, 이후 개선을 위한 데이터를 남기는 역할이 있습니다
관련 링크
- es-hangul — 한글 자모 분리·초성 추출·한영 변환 등을 제공하는 경량 라이브러리
- Algolia — 이번 프로젝트에서 사용한 검색 엔진 서비스
- Algolia
optionalWords— 일부 토큰만 겹쳐도 매칭되도록 하는 검색 파라미터 - Algolia Synonyms — 한/영 브랜드 매핑에 사용한 동의어 기능